10.1 强化学习的基本概念
10.1.1 强化学习是什么?
强化学习(Reinforcement Learning)通过不断试错和尝试的进行学习,并以以奖励作为指导改善学习者的行为。学习者不会被告知应该采取什么动作,而是自己通过尝试,去发现哪些动作会产生最丰厚的收益或者累积的奖励。在强化学习里,收益可能是多步决策的结果,即:当前的动作对未来的收益会产生影响。因此,我们可以称这种收益是延迟的收益。 通过试错来学习和延迟的收益,是强化学习两个最重要的特征。
在很长的一段时间里,强化学习被有监督学习(Supervised Learning)的光芒所遮掩。有监督学习是通过外部有知识的监督者提供的监督信号(label)来进行学习的。 值得注意的是,这种学习模式是和强化学习不同的,因为有监督学习可以从训练数据里获得标准的监督信号而不需要试错。
直到2013年,DeepMind发表了利用强化学习玩Atari游戏的论文[4],至此强化学习开始了新的十年。 2016年3月,通过自我对弈数以万计盘进行练习强化, 基于蒙特卡洛树搜索的强化学习模型AlphaGo[1]在一场五番棋比赛中4:1击败顶尖职业棋手李世石。 此后,一系列的被强化学习解决的问题和应用(application)如雨后的春笋一样冒出。 很多成功的应用都证明了强化学习是十分适合解决优化问题的一种方式, 这些应用包括:游戏,自动驾驶,路径规划,推荐系统,金融交易,控制等等。 而深度强化学习真正的发展归功于神经网络、深度学习以及计算力的提升。纵观近年的顶级会议论文,强化学习的理论和应用都进入了蓬勃发展期。
10.1.2 强化学习概念
下面介绍一些强化学习里的关键要素:环境(Environment), 智能体(Agent), 奖励(Reward), 动作(Action) ,状态(State)和策略(Policy)。 强化学习需要去环境里探索和学习一个最优的策略,使得在该策略下获得的奖励最大, 以解决当前的问题。
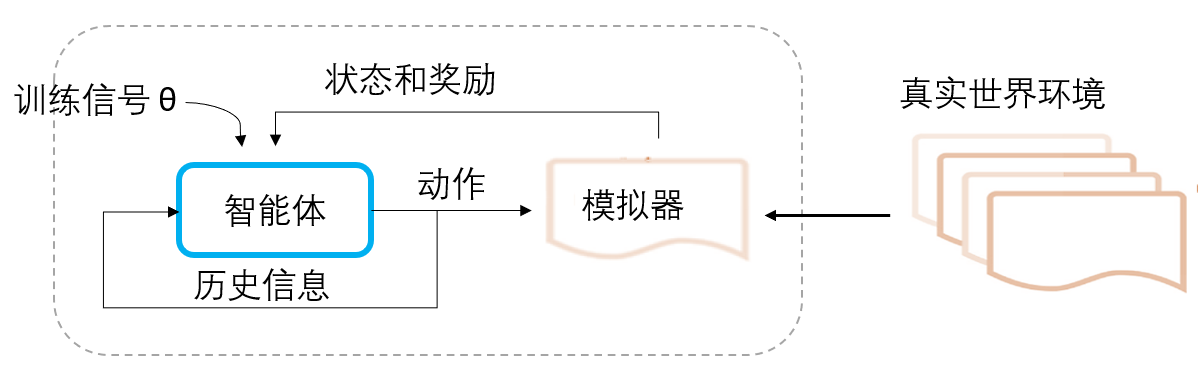
由于真实的环境复杂度较高,且存在很多与当前问题无关的冗余信息, 通常构建模拟器(Simulator)来模拟真实环境。智能体通常指做出决策的模型,即强化学习算法本身。智能体会根据当前这一时刻的状态 执行动作 来和环境交互;同时,环境会将智能体执行动作后到达的下一个时刻的状态 和这个动作拿到的奖励 返回给智能体。智能体可以收集一个时间段内的状态,动作和奖励等序列 $$(𝑎_1, 𝑠_1, 𝑟_1, . . . , 𝑎_𝑡, 𝑠_𝑡, 𝑟_𝑡)$$, 作为历史信息,并将其用来训练自身的强化学习模型。
例如,在众所周知的贪吃蛇小游戏里,智能体就是吃豆人。环境或者模拟器就是网格世界。智能体能观测到的状态是智能体在网格世界中的位置,豆子的位置或者途中鬼魂的位置。而智能体的动作包括了向上下左右运到的操作。当智能体吃到了豆子以后,会得到一个及时的奖励。
强化学习的目标是希望能在一段时间内获得的累积的奖励或者收益最大:
其中, , 表示一个折扣因子。 越大,表示智能体更关心长期奖励;而越小,表示智能体更关心短期奖励。表示一段时间。
对应在贪吃蛇的小游戏里,智能体的目标是吃掉网格中的食物,同时避开途中的鬼魂。在这种情况下,玩家或者智能体追求的长期目标或者奖励是指累积的奖励值越大越好,并最终赢得比赛。
为了建立最优策略,智能体面临选择动作究竟是为了探索(Exploration)还是利用(Exploit)的两难境地。所谓探索,就是选择去尝试没有探索过的新状态。而所谓利用,是指利用已知的知识,选择能让智能体最大化累积奖励的动作;这种情况下,到达的状态通常是之前探索过的或者和之前探索过的状态比较相似。 为了平衡探索和利用,最好的策略可能牺牲短期的奖励。因此,智能体应该收集足够的信息,以便在未来做出最佳的整体决策。
强化学习模型包括策略(Policy)和价值函数(Value Function)。智能体需要根据策略去决定做出什么样的动作。策略可以分为:
1)决定性的策略(Deterministic Policy)
2)非决定性的策略(Non-Deterministic Policy)
在某些情况下,策略可能是一个简单的函数或者查询表。而在另一些情况下,它可能涉及大量的计算,也可能是用神经网络(Artificial Neural Network)来近似。
价值函数指的是在策略下能得到的未来的奖励的加权期望值:
其中, , 表示一个折扣因子,和累积奖励里提到的 的含义一致。
除此之外,强化学习里还涉及其他的概念。由于篇幅有限,本章只介绍一些后面章节可能设计到的简单的概念; 更多的基本概念可以参考[18]等。
10.1.3 强化学习用来解决什么问题呢?
真实世界很多问题需要根据动态变化的环境,做出正确的序列决策来解决。 而强化学习非常擅长解决这类问题,并在以下领域有广泛的应用:
1)游戏(例如: 围棋[1], Atari小游戏[4], Dota2[5], 麻将[6], 星际争霸[[17]](#suphx(#starcraft)等)。例如,对于围棋来说,不仅需要根据当前的局面来做出判断,还需要预测对手在未来多步落子的路径,来谋求一个最佳的当前的落子策略。而强化学习可以通过自我博弈等方式,来有效的从数据里学习下棋的规律;
2)自动驾驶 ([13], [14], [15]等)。对于自动驾驶来说,通常需要根据规划的路径以及周围车辆的情况,来决定采取什么样的操作(加速,减速,刹车等)。而强化学习可以在模拟器里,学习到在什么样得路况下,采取什么样的操作可以让驾驶保证安全到达目的地;
3)路径规划 ([16]等)。路径规划里通常存在很多NP-hard的问题,求解这些问题通常需要很高的复杂度或者很多的算力。而强化学习可以从大量的数据里,学习到一些路径规划的策略,从而使得求解问题的复杂度更小,速度更快。例如,最经典的旅行商问题,强化学习可以规划从A城市到B城市,在必须遍历某些城市的约束下,路径如何走能花费最小;
4)推荐系统 ([8], [9], [10]等)。例如新闻推荐系统,强化学习可以根据用户的反馈(阅读时间等),来决定在首页推荐什么样的新闻,新闻放置的位置或者是否要做个性化推荐等。
5)金融交易 ([7])。金融领域涉及时间序列预测的问题,通常也可以强化学习来解决。例如,强化学习模型,通过学习海量历史数据里的股价变化的模式,根据当前的状态决定是要买入或者卖出股票。
6)控制 ([11], [12]等)。强化学习理论和控制论有很大的相关性,因而强化学习的框架也可以用来解决一些控制的问题。 例如,在模拟的环境里,通过让让机器人不断地试错,让机器人学会走路,跑步等。
由此可见,许多领域问题一旦涉及到需要根据动态环境做决策的序列优化问题,都可以抽象成用强化学习解决的问题。小到虚拟环境里的游戏,大到生物物种的进化,都可以看成是一个在变化的环境里探索正确生存之道的问题。
在接下来的小节里,我们会进一步讨论强化学习和传统机器学习,以及自动强化学习之间的区别和联系。
10.1.4 强化学习与传统机器学习的区别
机器学习可以分为三类,分别是有监督学习(Supervised Learning),无监督学习(Unsupervised Learning) 和强化学习(Reinforcement Learning)。
强化学习与其他机器学习不同之处在于:
强化学习不需要预先标记的数据集;相反,它通过与环境/模拟器的交互并观察其反馈,以经验的形式获取训练数据;
智能体执行的动作将会影响后面收集到的数据的分布。因而大多数的强化学习(除了离线强化学习)的训练和采样数据过程会互相影响;
基于1)和 2)的两点,强化学习在训练过程中,数据的分布是不断变化的;而有监督学习通常整体数据的分布是相对稳定的;
强化学习通过奖励去学习。而奖励或者有延时,不是能立即返回。对于某些特定环境来说,奖励可能是稀疏的,是在执行了多动作以后才能得到一个奖励。例如,对于围棋来说,必须到最后才知道棋局的胜负;而有监督学习通常根据标签(label)去学习,标签通常是和样本一一对应的;
10.1.5 强化学习与自动机器学习的区别
自动化机器学习(AutoML)包含一组技术(例如超参数优化(Hyper-parameters Optimization),自动特征工程(Automatic Feature Engineering),神经网络结构搜索(NAS)等),用于自动化地设计机器学习算法和模型。
强化学习是机器学习的一个子领域,涉及在环境中做出决策和采取行动以最大化(长期)奖励的任务。因而强化学习可以用来解决一些优化问题,为特定问题寻找最优地策略。
强化学习和自动机器学习是一个你中有我,我中有你的关系。
小结与讨论
本章我们主要围绕强化学习是什么,强化学习概念,强化学习解决的问题等。最后我们还绕强化学习与传统机器学习,自动机器学习的区别展开介绍。
参考文献
- Silver D, Huang A, Maddison C J, et al. Mastering the game of Go with deep neural networks and tree search[J.. nature, 2016, 529(7587): 484-489.
- Pham H, Guan M, Zoph B, et al. Efficient neural architecture search via parameters sharing[C.//International Conference on Machine Learning. PMLR, 2018: 4095-4104.
- Zhang J, Hao J, Fogelman-Soulié F, et al. Automatic feature engineering by deep reinforcement learning[C.//Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems. 2019: 2312-2314.
- Mnih V, Kavukcuoglu K, Silver D, et al. Playing atari with deep reinforcement learning[J.. arXiv preprint arXiv:1312.5602, 2013.
- Berner C, Brockman G, Chan B, et al. Dota 2 with large scale deep reinforcement learning[J.. arXiv preprint arXiv:1912.06680, 2019.
- Li J, Koyamada S, Ye Q, et al. Suphx: Mastering mahjong with deep reinforcement learning[J.. arXiv preprint arXiv:2003.13590, 2020.
- Liu X Y, Yang H, Chen Q, et al. Finrl: A deep reinforcement learning library for automated stock trading in quantitative finance[J.. arXiv preprint arXiv:2011.09607, 2020.
- Zheng G, Zhang F, Zheng Z, et al. DRN: A deep reinforcement learning framework for news recommendation[C.//Proceedings of the 2018 World Wide Web Conference. 2018: 167-176.
- Chen S Y, Yu Y, Da Q, et al. Stabilizing reinforcement learning in dynamic environment with application to online recommendation[C.//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 1187-1196.
- Wang X, Chen Y, Yang J, et al. A reinforcement learning framework for explainable recommendation[C.//2018 IEEE international conference on data mining (ICDM). IEEE, 2018: 587-596.
- Johannink T, Bahl S, Nair A, et al. Residual reinforcement learning for robot control[C.//2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019: 6023-6029.
- Kober J, Bagnell J A, Peters J. Reinforcement learning in robotics: A survey[J.. The International Journal of Robotics Research, 2013, 32(11): 1238-1274.
- Sallab A E L, Abdou M, Perot E, et al. Deep reinforcement learning framework for autonomous driving[J.. Electronic Imaging, 2017, 2017(19): 70-76.
- Wang S, Jia D, Weng X. Deep reinforcement learning for autonomous driving[J.. arXiv preprint arXiv:1811.11329, 2018.
- Kiran B R, Sobh I, Talpaert V, et al. Deep reinforcement learning for autonomous driving: A survey[J.. IEEE Transactions on Intelligent Transportation Systems, 2021.
- Zhang B, Mao Z, Liu W, et al. Geometric reinforcement learning for path planning of UAVs[J.. Journal of Intelligent & Robotic Systems, 2015, 77(2): 391-409.
- O. Vinyals, I. Babuschkin, W. M. Czarnecki, M. Mathieu, A. Dudzik, J. Chung, D. H. Choi, R. Powell, T. Ewalds, P. Georgiev and others, "Grandmaster level in StarCraft II using multi-agent reinforcement learning," Nature, vol. 575, p. 350–354, 2019.
- Sutton R S, Barto A G. Reinforcement learning: An introduction[M.. MIT press, 2018.